Creating Test Data
A Basic Program to Create Test Data
Limiting
the Output Record Count
Changing
Record and File Format (VSAM)
Files
with Multiple Record Layouts
Creating
Larger Test Files Without Input.
Creating Test Data from Production Files
System
Requirements when Creating Files
Introduction
MANASYS Jazz makes it easy to create test data files, either by selecting and modifying production data, or from program logic alone, so this is what this Users’ Guide chapter is about. There is an overlap between this section and Creating Test Data for Jazz Tutorials, but there the emphasis is on creating the files that you need for the Jazz tutorials and demonstrations. Here the emphasis is on general test data and the techniques you may use for your own systems. As you will see, it is possible to create “invalid” records, such as records referencing missing look-up data, numeric values out of range, etc. Indeed, you will do this deliberately in order to test how your programs deal with this problem. The converse issue, checking a file to ensure that nothing in it is invalid, will be one of the subjects of the next Users’ Guide chapter, System Discovery and Validation.
This
chapter will assume that you have at least a basic familiarity with MANASYS
Jazz: if this is your first contact with it, you should view the Initial
Demonstration video
Creating Test Data
Developers often create test data by copying a production file. After all, this is easy and quick. But 10,000 normal records don’t check that your program will handle one abnormal one, and what are your chances of noticing that record 7693 displays a non-fatal error? It is worth taking the time to prepare a good test file, large enough to exercise basic limits like page or form overflows, small enough that you can check all the results and grand totals, and diverse enough that it includes the boundary conditions like maximum and minimum values, and invalid values that may have slipped through data entry. Good test files will exercise not only the normal paths of your program, but unusual and error situations also. They become valuable software assets, evolving as new functions are added to your system, and proving not only that new functions work correctly but that you haven’t introduced errors in the processing of old functions.
We start with a basic file copy program, and then progress through a series of more complex situations. If a section such as Files with Multiple Record Layouts or Creating Files Without Input is not relevant to you you can skip these sections, coming back to them only if/when they do become relevant.
A Basic Program to Create Test Data
To create test data your program will have a loop containing a WRITE statement. Most commonly this loop will be defined by PROCESS, reading an input file from which you’ll select and modify data.
We start as most users will, by creating a test data file from an existing file. You need to have a Jazz record description for the input file, which you can create from a COBOL or SQL definition, or write manually. Here is the definition of sequential file IN1, one of the Jazz Tutorial files, which we’ll use for our first test data example.
*# Last Updated by JazzUser
at 14/05/2019 2:15:39 PM
COPY Types;
DEFINE IN1 VB DATA(
Region DECIMAL(3),
District DECIMAL(3),
Name CHAR(40),
SalesThisMonth MONEY(7,2),
SalesYTD MONEY(7,2),
BillingCycle LIKE Types.Month,
DateCommenced DATE DPIC 'dd mmm yyyy')
DSNAME 'JAZZUSER.FILES.IN1';
Note that the Jazz definition contains more information than a COBOL copy book. In particular it contains the file’s organization, VB, and its location, DSNAME 'JAZZUSER.FILES.IN1'.
We start by creating a program to copy this file. From the Jazz Workbench click [JazzGen] (or menu File/New), and select the option Logic/Batch Program. Give the program a name, select IN1 as input, give a name for the output, and check LIKE Input.
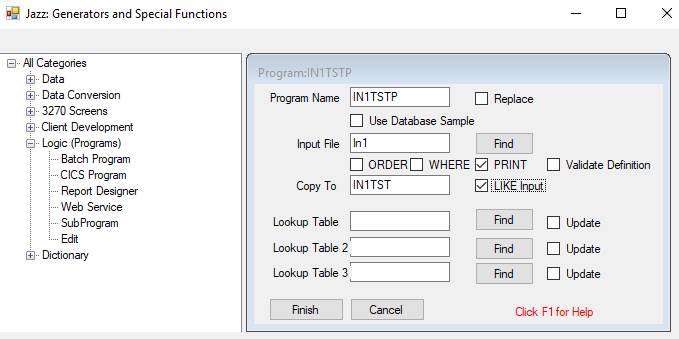
Click [Finish] and the workbench responds with a dialog to select which fields from IN1 we want. Instead of expanding the definition we click its name, to select everything: -

Click [Finish] and the workbench responds with this program: -
PROGRAM IN1TSTP BATCH;
* You may need to edit these statements
COPY In1;
DEFINE IN1TST LIKE IN1;
#492 I DSNAME 'JAZZUSER.FILES.IN1TST'
DEFINE Copy-Stats DATA(
*
Add any fields to be summed. For especially
large files ensure fields have enough digits
Input-Count INTEGER,
Output-Count INTEGER);
PROCESS In1 INDEX Copy-Stats.Input-Count;
COPY JZSMth;
PRINT (IN1.*) ;
IN1TST=IN1;
WRITE IN1TST;
#378 W Batch WRITE used - you may need to edit the JCL
Copy-Stats.Output-Count
+= 1;
* Add statements like 'Copy-Stats.Amount += IN1TST.Amount;' as relevant
END PROCESS In1;
PRINT (Copy-Stats.*) FIELDTABLE;
[JazzGen] has created a program that will read file IN1 and
copy it to IN1TST. As it does this it
will print the input records, and calculate input and output record counts
which are printed at the end. IN1TST has
the same format and data as IN1. This
generated program is only a starting point, and there are a number of changes
that we’ll want to make.
Note that
the WRITE statement is followed by message
#378. Before you attempt to run it see System Requirements when Creating Files/PSAM below.
Limiting
the Output Record Count
For test data we usually want only
enough records, we don’t want the full number of records from a production
file. INDEX Copy-Stats.Input-Count
is already
counting the records read for us, all we need to do is add UNTIL to the PROCESS: -
PROCESS In1 INDEX Copy-Stats.Input-Count UNTIL Output-Count >= 200;
Click [Check] and this becomes
PROCESS In1 INDEX Copy-Stats.Input-Count UNTIL
Copy-Stats.Output-Count
>= 200;
#199 W
Reference to a field in the current file expected
Now only
200 records will be written.
At this
stage it doesn’t matter whether we use Input-Count or Output-Count, but with
more logic in our program, perhaps including record selection, you might not be
writing every record that you read.
Record
Order
If we want the output to be in a
particular order, then add ORDER IN1.? to the PROCESS statement, and click [Check] to initiate a dialog to choose
the ordering fields: -
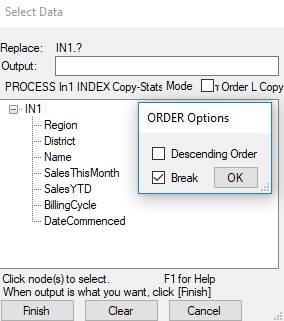
Selecting Region, District, and
Name, with BREAK not checked, results in
ORDER(IN1.Region,IN1.District,IN1.Name);
being added
to the PROCESS statement, so input is read and the
output written in this order.
Changing Record and File Format (VSAM)
We didn’t have a defined record
layout for IN1TST, so we checked LIKE input
![]()
Jazz generated a definition which
was identical to IN1 except for the DSNAME: -
DEFINE IN1TST LIKE IN1;
#492 I DSNAME 'JAZZUSER.FILES.IN1TST'
Data was assigned from IN1 to IN1TST
with a single whole-record assignment.
IN1TST=IN1;
If we had an existing definition of
the output file we wouldn’t have checked LIKE
Input. With this: -
![]()
Jazz generates COPY Custf; instead of DEFINE
IN1TST LIKE IN1. Here
is the definition of CustF: -
COPY Types;
DEFINE CustF
VSAM DATA(
Account PIC '999999' HEADING 'Account Number' KEY,
Region DECIMAL(3),
District DECIMAL(3) RANGE(1:10),
Name CHAR(30) CAPS DKEY 'jazzuser.vsam.custf1',
SalesThisMonth MONEY(7,2),
SalesYTD MONEY(7,2),
Billingcycle LIKE Types.Month,
DateCommenced DATE)
DSNAME 'JAZZUSER.VSAM.CUSTF';
Unlike creating
IN1TST, to create CUSTF we are both reformatting the record and changing the
file organization. Here is program
CR8Cust: -
PROGRAM Cr8Cust BATCH;
COPY In1;
COPY Custf;
DEFINE Copy-Stats DATA(
Input-Count INTEGER,
Output-Count INTEGER);
PROCESS In1 INDEX Copy-Stats.Input-Count;
COPY JZSMth;
PRINT (IN1.*) ;
CustF.*=In1.*;
#207 I Region,District,Name,SalesThisMonth,SalesYTD,BillingCycle,DateCommenced,
included in generic assignment
WRITE Custf;
#348 W VSAM file must be empty
Copy-Stats.Output-Count
+= 1;
END PROCESS In1;
PRINT (Copy-Stats.*) FIELDTABLE;
Firstly,
note that the assignment is not now a single whole-record assignment, but is
now a generic assignment in which each like-named field is assigned
individually: -
CustF.*=In1.*;
#207 I Region,District,Name,SalesThisMonth,SalesYTD,BillingCycle,DateCommenced,
included in generic assignment
In fact
most fields have the same format in both records, except NAME which is CHAR(40) in IN1 and CHAR(30) in Custf. In a more general case
any of the fields named in message #207 could have had a different, but
compatible format. For example Region in one file could be SMALLINT instead of DECIMAL(3). If
fields were incompatible, for example one is CHAR and the other a number, then they would have
been excluded from the generic assignment.
Generic assignments only deal with
like-named compatible fields. Custf.Account is not named in In1, so we need to
give it a value. In fact
it is the VSAM record’s primary key, so that when
we create the file through this loop we must ensure that each record has a
unique value, and that Custf.Account values are given in ascending sequence. With its PIC definition, meaning that it is a number in
character format, this is easy. We just
write Account = Input-count; within the PROCESS loop, which Jazz changes to
CustF.Account
= Copy-Stats.Input-Count;
when we click
[Check]. The input and output records
are different, so of course we change the PRINT statement to print the output
record, and move it after all the assignments to Custf.
Now the process loop looks like this: -
PROCESS In1 INDEX Copy-Stats.Input-Count;
CustF.*=In1.*;
#207 I Region,District,Name,SalesThisMonth,SalesYTD,BillingCycle,DateCommenced,
included in generic assignment
CustF.Account = Copy-Stats.Input-Count;
#361 E Assignment to a key field
PRINT (CustF.*);
WRITE Custf;
#348 W VSAM file must be empty
Copy-Stats.Output-Count
+= 1;
END PROCESS In1;
We check
error #361 (right-click the error message), and find that in this situation
there is no problem.
Message
#348 tells is that to create a VSAM file with a WRITE statement like this the VSAM file must be empty. Is it?
See System Requirements when Creating Files/VSAM
below. Create (or ReCreate)
the cluster, as described there, but do not create alternate indexes. With an empty cluster, but without its
alternate indexes defined, we’re ready to compile and run the program to create
VSAM test data. It is essential that the
records are written in order of ascending primary key. The way we’ve calculated CustF.Account guarantees this, but if the value
comes from the input source then our PROCESS statement must use an appropriate ORDER. Once
the cluster has been filled with data, if the file requires one or more
alternate indexes then these are created.
Files with Multiple Record Layouts
Sequential
files may be filled with many different record layouts. For example, a file may start with a header
record giving information such as the date and time that this file was written,
followed by a number of detail records, and then the file ends with a trailer
record, giving control totals such as a record count, and sums of key values
such as the total account balance. Or
you may find a record containing different types of records, for example with
different formats for different types of credit cards. Such files start with a
definition of the longest record possible, and then other record types are
defined using REDEFINES. Definition FILEIN, which is a subset of a
real example, shows the concept. COPY FILEIN; brings definitions into our program
that contains three DEFINE
statements: -
DEFINE FILEIN VB DATA(
COMMON GROUP,
ORG PIC '999',
AFF CHAR(4) CONDITIONS('X1 ','X2 ','X3 ','X4 ','X5 ','X6 ','X7 ','X8 ','X9 ','XA ','XB ','XC ','XD ','XE ','XF ','XG ','XH ','XI ','XJ ','XP ','XS ':VALID-XX-AFF),
REC-STAT PIC '9',
END GROUP,
FILLER CHAR(10284)) DSNAME 'MANAJAZZ.FILES.FILEIN';
DEFINE FILE-HDR-RECORD REDEFINES DATA(
FILLER LIKE FILEIN.COMMON,
HDR-PROC-DATE DECIMAL(7),
HDR-TIME-STAMP DECIMAL(11));
DEFINE FILE-X-USA-RECORD REDEFINES DATA(
FILLER LIKE FILEIN.COMMON,
VI-X-QP-REGION CHAR(1),
VI-MC-QP-REGION CHAR(1),
VI-EU-QP-REGION CHAR(1),
FILLER CHAR(194));
This
first definition is often a dummy, as here, just to establish a base for the
redefinition. The beginning of every
record must have the same layout in all record types, and will contain
sufficient information to be able to determine what type of record we’re
dealing with. Here the first eight bytes, containing fields ORG, AFF, and REC-STAT, is always present whatever the record type,
and the program can determine the record type with logic using these fields. It
is preferable but not compulsory to use a GROUP to contain these common fields, is as it
allows us to write
FILLER LIKE FILEIN.COMMON
instead of
risking errors with
FILLER CHAR(8).
The FILEIN
copy book continues with the 2nd and 3rd
definitions. Each definition uses REDEFINES, meaning that FILE-HDR-RECORD and FILE-X-USA-RECORD occupy the same memory as the preceding record,
FILEIN. The
first field is FILLER CHAR(8). “FILLER” is a special name with
the same meaning in Jazz as in COBOL: it is a field that takes up space, but
cannot be referenced. You don’t need to
refer to FILE-HDR-RECORD.ORG, as you can refer to FILEIN.ORG to
refer to the first 3 bytes of FILE-HDR-RECORD.FILLER.
With a
definition such as this you can create a file to copy some records from it to
create test data, starting with the same kind of [JazzGen] dialog that was used to create IN1TSTP or program CR8Cust. The generated program looks like this. It
will need significant modification: -
PROGRAM FILEC BATCH;
* You may need to edit these statements
COPY Filein;
COPY FileO;
DEFINE Copy-Stats DATA(
*
Add any fields to be summed. For
especially large files ensure fields have enough digits
Input-Count INTEGER,
Output-Count INTEGER);
PROCESS Filein
INDEX Copy-Stats.Input-Count;
COPY JZSMth;
FILEO.*=Filein.*;
#207 I COMMON.ORG,COMMON.AFF,COMMON.REC-STAT,
included in generic assignment
WRITE FileO;
#378 W Batch WRITE used - you may need to edit the JCL
Copy-Stats.Output-Count
+= 1;
* Add statements like 'Copy-Stats.Amount += FileO.Amount;' as
relevant
END PROCESS Filein;
PRINT (Copy-Stats.*) FIELDTABLE;
Here COPY FileO gives the output definition, which
is similar to the input definition and starts with a common record layout: -
DEFINE FILEO VB DATA(
COMMON GROUP,
ORG PIC '999',
AFF CHAR(4) CONDITIONS('X1 ','X2 ','X3 ','X4 ','X5 ','X6 ','X7 ','X8 ','X9 ','XA ','XB ','XC ','XD ','XE ','XF ','XG ','XH ','XI ','XJ ','XP ','XS ':VALID-XX-AFF),
REC-STAT PIC '9',
END GROUP,
FILLER CHAR(10284)) DSNAME 'MANAJAZZ.FILES.FILEIN';
and continues
with the redefinitions. Or
alternatively, if we don’t want to make layout changes: -
COPY Filein;
DEFINE FILEO VB LIKE FILEIN
DSNAME 'MANAJAZZ.FILES.FILEO';
#145 W FILEIN has redefinitions
DEFINE FILEO-HDR-RECORD REDEFINES LIKE FILE-HDR-RECORD;
DEFINE FILEO-X-USA-RECORD REDEFINES LIKE FILE-X-USA-RECORD;
As
initially generated, there are two major problems. Firstly, FILEO.*=Filein.*; will assign only the three fields of the common
area. Nothing is assigned to the fields
of FILEO-HDR-RECORD and FILEO-X-USA-RECORD,
whatever type of input record has been read.
Secondly, WRITE FileO; writes the full length, 10292 bytes, of record FILEO, whatever the
record type read from FILEIN. Who knows
what’s in the 10284 characters of FILLER following the 8 bytes of COMMON?
We edit the
program like this: -
1.
Following
the common assignments, we write logic to detect which record type we’re
dealing with, and assign data for the appropriate record type. For example
IF FILEIN.ORG=0;
[Header
FILEO-HDR-RECORD.* = FILE-HDR-RECORD.*;
2.
The
basic WRITE statement is modified, adding (Record.*)
to name one of the record types defined in the output file: -
WRITE
FILEO(FILEO-HDR-RECORD.*);
3.
Copy-Stats
are modified to count the number of records written of each type.
4.
The
PROCESS loop is limited to writing 200 X-USA records.
5.
The
unwanted comments and PRINT statement are removed
Here is the
complete program: -
PROGRAM FILEC BATCH;
COPY FILEIN;
COPY FILEO;
COPY JZSMth;
DEFINE Copy-Stats DATA(
Input-Count INTEGER,
Hdr-Count INTEGER,
X-USA-Count INTEGER);
PROCESS FILEIN INDEX Copy-Stats.Input-Count UNTIL
Copy-Stats.X-USA-Count
>= 200;
#199 W Reference to a field in the current file expected
*
$Common
FILEO.* = FILEIN.*;
#207 I COMMON.ORG,COMMON.AFF,COMMON.REC-STAT,
included in generic assignment
IF FILEIN.ORG=0; [Header
FILEO-HDR-RECORD.* = FILE-HDR-RECORD.*;
#207 I HDR-PROC-DATE,HDR-TIME-STAMP,
included in generic assignment
Copy-Stats.Hdr-Count += 1;
WRITE FILEO(FILEO-HDR-RECORD.*);
#378 W Batch WRITE used - you may need to edit the JCL
ELSEIF FILEIN.AFF=VALID-XX-AFF;
[X-USA-RECORD
FILEO-X-USA-RECORD.* = FILE-X-USA-RECORD.*;
#207 I VI-X-QP-REGION,VI-MC-QP-REGION,VI-EU-QP-REGION,
included in generic assignment
Copy-Stats.X-USA-Count += 1;
WRITE FILEO(FILEO-X-USA-RECORD.*);
#378 W Batch WRITE used - you may need to edit the JCL
END IF;
END PROCESS FILEIN;
PRINT(Copy-Stats.*)FIELDTABLE;
This
example program was based on a production program that converted a file
containing many different record types, and has been greatly simplified to
demonstrate simply the key points of creating files with multiple record
layouts. The key concepts are: -
1.
Define
a series of records using REDEFINES
2.
After
handling the common data, use IF or CASE logic to determine what record type is being
processed
3.
Use
WRITE (record) to write
the correct record type.
Within type-specific logic you
should only refer to fields for the correct type. For example, this code cannot be correct, but
Jazz can’t detect this problem and unpredictable errors will occur when the
program is executed: -
IF FILEIN.ORG=0; [Header
FILEO-X-USA-RECORD.VI-X-QP-REGION = SPACE;
Creating Small Files Without Input
What if we
don’t have an input file to read and modify?
Suppose we want to create a simple file like FR, used in the
demonstrations as a simple VSAM file that can give Region Name from a Region Nbr. Here is its
definition: -
DEFINE FR VSAM DATA(
Region PIC '999' KEY RANGE (1:20),
Name CHAR(30) VALUE('No Record found')
HEADING 'Region
Name',
Fill CHAR(47))
DSNAME 'JAZZUSER.VSAM.Region';
We want to
create it with this data: -
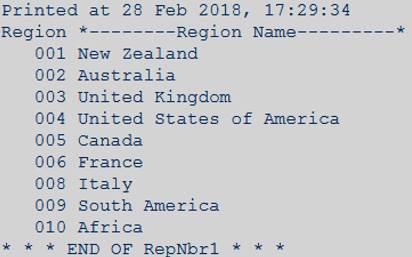
As before
we create a program with a loop containing a WRITE statement, but now the loop
will be controlled by a FOR statement. We start by creating a program with [JazzGen] Logic/Batch program. Since we’re not reading any input files we give nothing but the program name. Only the PROGRAM statement is generated: -
PROGRAM Cr8FR BATCH;
* You may need to edit these statements
We write
logic to write these records: -
PROGRAM Cr8FR BATCH;
Copy FR;
For IX = 1 to 10;
If IX <> 7 then; [omitted to test
record-not-found
FR.Region = IX;
Write FR;
end if;
End for;
When
[Check] is clicked this becomes
PROGRAM Cr8FR BATCH;
COPY FR;
FOR JZ.IX
= 1 TO 10;
IF JZ.IX
<> 7 THEN; [omitted to test
record-not-found
FR.Region
= JZ.IX;
#361 E Assignment to a key field
WRITE FR;
#348 W VSAM file must be empty
END IF;
END FOR;
A table of region
names is defined, and one of these assigned to FR.Name. A
PRINT statement completes our program: -
PROGRAM Cr8FR BATCH;
COPY FR;
DEFINE W DATA(
RName(10)
CHAR(30) VALUE ('New Zealand','Australia','United Kingdom',
'United States of America',
'Canada', 'France', ' ', 'Italy', 'South America', 'Africa')
);
FOR JZ.IX
= 1 TO 10;
IF JZ.IX
<> 7 THEN; [omitted to test
record-not-found
FR.Region
= JZ.IX;
#361 E Assignment to a key field
FR.Name
= W.RName(JZ.IX);
COPY JZSMth;
PRINT(FR.Region, FR.Name);
WRITE FR;
#348 W VSAM file must be empty
END IF;
END FOR;
As above,
message #348 reminds us that for this program to work we must create an empty VSAM cluster before it we run it.
Creating
Larger Test Files Without Input.
File IN1
that we read to create file IN1TST is larger than FR, containing 300 records,
and several fields. Here is its definition: -
COPY Types;
DEFINE IN1 VB DATA(
Region DECIMAL(3),
District DECIMAL(3),
Name CHAR(40),
SalesThisMonth MONEY(7,2),
SalesYTD MONEY(7,2),
BillingCycle LIKE Types.Month,
DateCommenced DATE DPIC 'dd mmm yyyy')
DSNAME 'JAZZUSER.FILES.IN1';
Creating
300 records in this file, with 7 fields in a variety of formats, will be
tedious if we have to write out values for every record as we did for FR. Your files may have even more fields, and you
may want more than 300 records. Here’s
how I created IN1.
CHAR
(and VARCHAR) data
First I wanted NAME to be more realistic than “Name 001” etc. I had a suitable file in a SQL database on my laptop, so I opened this and copy/pasted it into Notepad, where I edited into a list of values delimited with quotes and separated by commas. I turned this into a DEFINE statement, and created a Jazz Copy book called TestData. I added line 2 of the values,
'BARNES, Alf, Maximum length value xxxEND',
to ensure that there was at least one maximum-length field. Here is the start of this definition: -
*# Last Updated by JazzUser
at 8/07/2019 11:14:45 AM
DEFINE Testdata
DATA(
* 300 names of dead people from a family
tree. Max name lth is 40, ascending
alpha order
Names(300) CHAR(40) VALUE(
'BANFIELD, Nora Joyce Annie', 'BARKMAN, Olivia Martha', 'BARNES, Albert Paul',
'BARNES, Alf, Maximum length value xxxEND',
'BARNES, Ann','BARNES,
Arthur Cyril','BARNES,
Caroline',
'BARNES, Edward John','BARNES, Edward','BARNES, Hannah Francis',
'BARNES, Harold Victor','BARNES, Harriet Francis','BARNES, Henry Maurice',
'BARNES, Henry','BARNES,
Hilda','BARNES,
Jessie Crawford',
You may be able to create a similar resource from your own files, or you can use COPY TestData; which is supplied with the training objects when you install Jazz. Data is taken from a genealogy file, so there’s no privacy issue as all the names are of dead people.
Here’s the program so far, writing out IN1 records with IN1.Name values only.
PROGRAM IN1W BATCH;
COPY IN1;
COPY TestData;
FOR Testdata.Names(JZ.IX1);
IN1.Name = Testdata.Names(JZ.IX1);
WRITE In1;
#378 W Batch WRITE used - you may need to edit the JCL
END FOR;
Note
the use of FOR Testdata.Names(JZ.IX1). By referring to the table
instead of writing FOR JZ.IX1 = 1 TO 300 we can’t get the number wrong.
Numbers
The COBOL
RANDOM function is a convenient way to set a numeric value. It returns a random floating
point number between 0.00000 and 0.99999, so with a bit of arithmetic we
can convert this to the range that we want.
For IN1.Region, defined DECIMAL(3), I wanted
a number from 1 to 10, so I wrote
IN1.Region = COBOL.RANDOM * 9 + 1;
Without * 9 + 1 every value would be zero as the decimal fraction would be dropped. * 9 converts this to a value from 0.00000 to 9.99999, so + 1 makes this a value from 1 to 10. Similarly,
IN1.District = COBOL.RANDOM * 6 + 1;
gives IN1.District a value from 1 to 7, and
IN1.SalesThisMonth =
COBOL.RANDOM *
10000;
sets it to a value up to $10,000.00, retaining two digits of decimals.
IN1.BillingCycle is defined BillingCycle LIKE Types.Month, and Types.Month is defined
Month CODES(January,February,March,April,May,June,July,August,September,October,November,December),
So IN1.BillingCycle is a single-byte number (TINYINT) with a value in the range 1:12. These statements set JZ.IX2 to a value in this range, then use this to calculate IN1.SalesYTD and to set IN1.BillingCycle.
JZ.IX2= COBOL.RANDOM * 11 + 1; [number from 1 to 12
IN1.SalesYTD = IN1.SalesThisMonth *
JZ.IX2;
IN1.BillingCycle =
JZ.IX2;
DATE fields
DATE fields like IN1.DateCommenced are numbers in the format yyyymmdd, e.g. the 28th February 2018 would be 20180228. The value must be a valid date, we can’t simply assign a random number to the field, so I chose to set all the values to a single date. If you want random DATE values, assign a constant date like this, then use date arithmetic to add random numbers of days, months, or years. There is an example of this below in Program GenPJ2.
Program IN1W
After adding a PRINT statement, here is the complete program to write file IN1: -
PROGRAM IN1W BATCH;
COPY IN1;
COPY TestData;
COPY JZSMth;
FOR Testdata.Names(JZ.IX1);
IN1.Region = COBOL.RANDOM * 9 + 1;
IN1.District = COBOL.RANDOM * 6 + 1;
IN1.Name = Testdata.Names(JZ.IX1);
IN1.SalesThisMonth =
COBOL.RANDOM *
10000;
JZ.IX2= COBOL.RANDOM * 11 + 1; [number from 1 to 12
IN1.SalesYTD = IN1.SalesThisMonth *
JZ.IX2;
IN1.BillingCycle =
JZ.IX2;
#072 W Value directly assigned to a Coded field. It may be invalid
IN1.DateCommenced =
'28 Feb 2018';
#568 I Date Value is 28 Feb 2018
PRINT (JZ.IX1,IN1.Region,IN1.District,IN1.Name, IN1.SalesThisMonth,IN1.SalesYTD,IN1.BillingCycle,IN1.DateCommenced);
WRITE In1;
#378 W Batch WRITE used - you may need to edit the JCL
END FOR;
Creating SQL Tables
There are only a few minor differences when creating SQL test data. For example, suppose that we want to create a new table that is similar to table PROJACT in the DB2 Sample database supplied by IBM. There are 65 records in this table, starting with
C:\Program Files\IBM\SQLLIB\BIN>db2 select * from projact
PROJNO ACTNO ACSTAFF ACSTDATE ACENDATE
------ ------ ------- ---------- ----------
AD3100 10 - 01/01/2002 -
AD3110 10 - 01/01/2002 -
AD3111 60 - 01/01/2002 -
AD3111 60 - 03/15/2002 -
AD3111 70 - 03/15/2002 -
…
All the values of ACSTAFF and ACENDATE are NULL. We want to create a new table called
PROJACT2 that is the same as this, except that we’ll supply values randomly for
the missing fields, and also add another field, “Person”, for the name of the
person assigned to this project activity.
We’ll write a program that copies data from PROJACT to PROJACT2,
modifying the records to add values of missing fields. We have a Jazz layout for PROJACT, but we
don’t yet have one for PROJACT2
The PROJACT definition was created by [JazzGen] Data/Import from SQL.
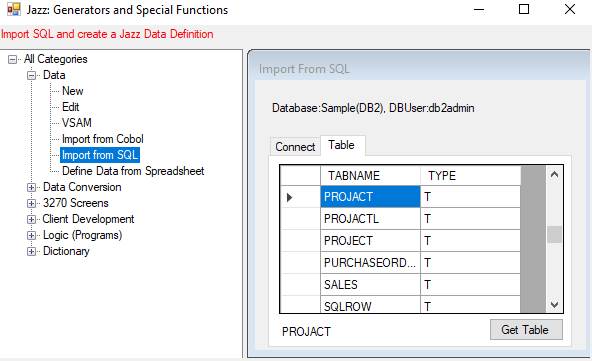
Jazz detected the three-part key and created all the code needed except that CAPS was added to the definition of PROJNO to prevent warning message #647. Here is the definition
*# Created from Table:PROJACT, Schema:Robertbw10, Database:sample
by JAZZUSR at 13/12/2019 2:04:01 PM
DEFINE PROJACT SQL DATA(
PROJNO CHAR(6) CAPS REQUIRED KEY,
ACTNO SMALLINT REQUIRED KEY PART 2,
ACSTAFF MONEY(5,2),
ACSTDATE DATE REQUIRED KEY PART 3,
ACENDATE DATE);
First we must define the output table PROJAC2 both to our DB2 Sample database and to Jazz. See System Requirements when Creating Files/SQL. With Method 1, Jazz to SQL, Table PROJAC2 has been defined to the database, and in this Jazz definition: -
DEFINE PROJAC2 SQL
PREFIX PJ2
DATA(
PROJNO CHAR(6) CAPS REQUIRED KEY,
ACTNO SMALLINT REQUIRED KEY PART 2,
ACSTAFF DECIMAL(5,2),
ACSTDATE DATE REQUIRED KEY PART 3,
ACENDATE DATE,
PERSON CHAR(30));
Now we generate a program that will copy PROJACT to PROJAC2: -
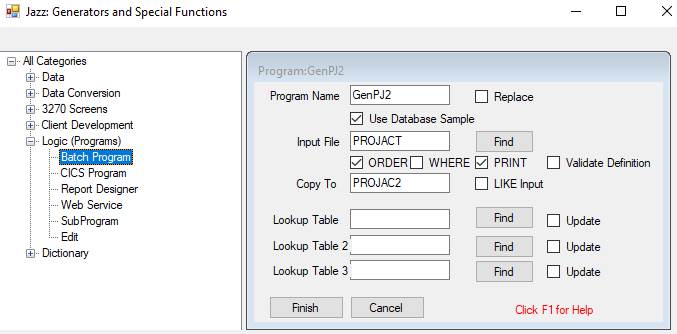
After selecting the key fields for ORDER, and the whole record for PRINT, this program results: -
PROGRAM GenPJ2 BATCH DATABASE Sample DB2;
* You may need to edit these statements
COPY PROJACT;
COPY PROJAC2;
DEFINE Copy-Stats DATA(
*
Add any fields to be summed. For especially
large files ensure fields have enough digits
Input-Count INTEGER,
Output-Count INTEGER);
PROCESS PROJACT ORDER(PROJACT.PROJNO,PROJACT.ACTNo,PROJACT.ACSTDATE)
INDEX Copy-Stats.Input-Count;
COPY JZSMth;
PRINT (PROJACT.*) ;
PROJAC2.*=PROJACT.*;
#207 I PROJNO,ACTNO,ACSTAFF,ACSTDATE,ACENDATE,
included in generic assignment
WRITE PROJAC2;
Copy-Stats.Output-Count
+= 1;
* Add statements like 'Copy-Stats.Amount += PROJAC2.Amount;' as relevant
END PROCESS PROJACT;
PRINT (Copy-Stats.*) FIELDTABLE;
This needs to be edited to give values to the missing fields ACSTAFF, ACENDATE and PERSON, and to print the output instead of input. Using RANDOM as we did earlier, the program has been edited to this: -
PROGRAM GenPJ2 BATCH DATABASE Sample DB2;
COPY PROJACT;
COPY PROJAC2;
COPY JZSMth;
COPY testdata;
COPY JZMDays;
DEFINE W DATA(Days DECIMAL(3));
DEFINE Copy-Stats DATA(
Input-Count
INTEGER,
Output-Count
INTEGER);
PROCESS PROJACT ORDER(PROJACT.PROJNO,PROJACT.ACTNO,PROJACT.ACSTDATE)
INDEX Copy-Stats.Input-Count;
PROJAC2.*=PROJACT.*;
#207 I PROJNO,ACTNO,ACSTAFF,ACSTDATE,ACENDATE, included in generic
assignment
* Set Person to a value from TestData. Leave
about 10% absent
JZ.IX1 = COBOL.RANDOM * 10;
IF JZ.IX1 > 0 THEN;
PROJAC2.PERSON
= Testdata.Names(JZ.IX1);
#539 W
PERSON is shorter than source: value may be truncated
END IF;
* Set staffing budget for this
item
PROJAC2.ACSTAFF
= COBOL.RANDOM
* 100;
* Set about 10% if records
finished by setting end date, 0 to 5 days from start
IF JZ.IX1 = 2 THEN;
W.Days =
COBOL.RANDOM *
6;
PROJAC2.ACENDATE
= PROJACT.ACSTDATE
+ W.Days;
#579 W Days
interpreted as days in range 0 to 365
END IF;
PRINT
(PROJAC2.*) ;
WRITE
PROJAC2;
Copy-Stats.Output-Count +=
1;
END PROCESS PROJACT;
PRINT (Copy-Stats.*) FIELDTABLE;
Here is part of the printout from this program. As it shows, a random value has been set for ACSTAFF, some records have had ACENDATE set to a date that is the same as or a few days later than ACSTDATE, and a name has been randomly chosen from the first 10 names: -
1Printed at 10 Jul 2019, 11:24:18 RepNbr1 Page 1
0PROJNO *ACTNO* ACSTAFF *ACSTDATE *ACENDATE
*-----------PERSON-----------*
0AD3100 10 80.47 01 Jan 02 00 *** 00 BARNES, Ann
AD3110 10
71.91 01 Jan 02 00 *** 00 BARNES, Arthur Cyril
…
AD3113 70
22.68 15 Oct 02 00 *** 00 BARNES, Edward John
AD3113 80
47.73 01 Jan 02 00 *** 00 BARNES, TEST, Maximum length
AD3113 80
17.74 01 Mar 02 00 *** 00 BARNES, Caroline
AD3113 180
45.94 01 Mar 02 04 Mar 02 BARKMAN, Olivia Martha
AD3113 180
83.86 15 Apr 02 00 *** 00 BARNES, Arthur Cyril
…
IF2000 110
29.80 01 Oct 02 00 *** 00 BANFIELD, Nora Joyce Annie
MA2100 10
97.90 01 Jan 02 03 Jan 02 BARKMAN, Olivia Martha
MA2100 20
88.03 01 Jan 02 01 Jan 02 BARKMAN, Olivia Martha
MA2110 10
77.36 01 Jan 02 00 *** 00 BARNES, TEST, Maximum length
MA2111 40
34.55 01 Jan 02 00 *** 00 BARNES, Caroline
MA2111 50
14.08 01 Jan 02 05 Jan 02 BARKMAN, Olivia Martha
…
PL2100 30
71.73 01 Jan 02 00 *** 00 BARNES, Edward John
0* Field Name * PR-LTH
VALUE
Copy-Stats.Input-Count : 14: 65
Copy-Stats.Output-Count: 14: 65
* * * END OF RepNbr1 * *
*
Creating Test Data from Production Files
You can easily create a test data file from a production file with the techniques shown here, modifying the output records to reflect various situations that you want to include in your tests. This will have the advantage of ensuring that related records exist in other files. You can then create a test file for the related data by copying (and modifying?) the related production file, perhaps omitting one of the records to ensure a test of record-not-found as we did for Region = 7 in File FR.
When you’re copying production data there may be privacy issues. For example, a few years ago my company was developing software for health clinics, and we needed realistic-looking test data for the on-line documentation that shipped with the software. In general, but particularly with medical records, you cannot afford to use the names of real people in any general publication. It would have been a large effort to make up manually create a few hundred new records from our imagination, and we already had a copy of our first-customer’s patient data, given to us to help develop the new system. This patient data contained a few hundred records with an index number, and fields including the patient’s family name, their given names, three lines of address, and other identifying information like their telephone number. We created a new table by copying this data with these transformations: -
1. The family name was replaced by the family name from another record, randomly selected. “*” was appended to the name.
2. The given names field was similarly replaced
3. Ditto each of the three address fields
4. The telephone number was set to 1234567 in all cases
Thus if record #248 of the original file had a record for
Family name: Barnes
Given Names: Robert Arthur
Address1: 13A Havenwood Place
Address2: Birkenhead
Address3: Auckland 0626
In the new table, records with different index values will be given the values from record #248. Perhaps: -
#23 Family name: Barnes*
#375 Given Names: Robert Arthur
#123 Address1: 13A Havenwood Place
#219 Address2: Birkenhead
#291 Address3: Auckland 0626
Record #248 will end up with completely different values
Family name: Wood*
Given Names: Mary Elizabeth
Address1: Upper Durham Road
Address2: Hamilton
Address3: New Zealand 0230
For this purpose it didn’t matter if the address was nonsensical to the NZ Post Office, or that we’d assigned a female given name to a male, it only had to look realistic. And with the * appended to Family Name, or telephone number = 1234567, it was immediately obvious to the development team and quality control whether documentation had been incorrectly created with live data or correctly with test data.
System Requirements when Creating Files
Although
the programs above may compile cleanly, they won’t necessarily run
correctly. Depending on the output file
type you may need to change the JCL, or define the file in a particular way,
before the WRITE
statement will execute correctly.
PSAM Files
Message #378 warns us about a
potential problem.
WRITE IN1TST;
#378 W Batch WRITE used - you may need to edit the JCL
For PSAM
files – types F, FB, V, VB, and U – JCL is generated
like this, which assumes that the file already exists: -
//GO EXEC PGM=IN1TSTP,TIME=(0,10)
//SYSOUT DD SYSOUT=*
//PRTERR DD SYSOUT=*
//SNAP DD SYSOUT=*
USED BY JZSTXIT
//* Inserted DD statements based on
program
//IN1 DD DSNAME=JAZZUSER.FILES.IN1,DISP=SHR
//IN1TST DD DSNAME=JAZZUSER.FILES.IN1TST,DISP=SHR
//REPNBR1 DD
SYSOUT=*
If the output file (here IN1TST) does not exist, then you must edit this JCL to change DISP, and add SPACE: -
//IN1TST DD DSNAME=JAZZUSER.FILES.IN1TST,DISP=(NEW,CATLG),
// SPACE=(TRK,(1,1))
You will not need to make this change if you re-run the
program, although you should change DISP=SHR to DISP=OLD if
there is any chance that some other program may try to access this data set at
the same time as your program is writing to it.
VSAM Files
Like message #378 above, message
#348 warns us about a potential problem
WRITE Custf;
#348 W VSAM file must be empty
VSAM files
are defined with the IDCAMS utility and must exist before we write their first
record, unlike PSAM we do not create a new (empty) VSAM file simply by changing
the JCL. The easiest way to do this is
to use [JazzGen].
Select Data/VSAM, and browse to the record layout. If you are creating the test data for the
first time, then give setting such as this, which will create an empty CustF cluster expecting about 300 records. If you have already created the test data
but you want to re-create it – perhaps you’ve updated the records and you want
to get back to your initial state, perhaps you’ve changed the record definition
or your program logic – then check ReCreate
Cluster. Do not check AIX.
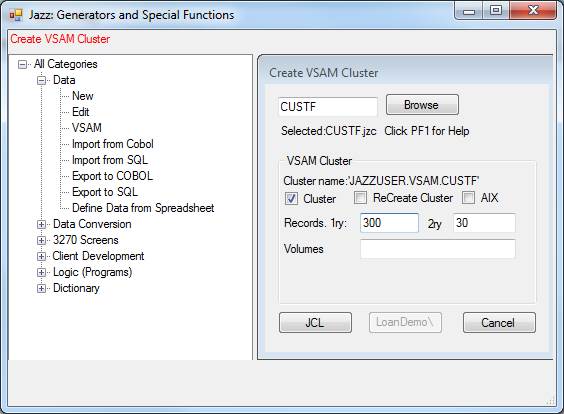
With these settings, Jazz will have created this JCL to create the VSAM cluster: -
//JAZZUSER JOB ,CLASS=A,MSGCLASS=A
//JZVSAM2 EXEC PGM=IDCAMS
Manage VSAM Data Sets
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
DEFINE CLUSTER (NAME (JAZZUSER.VSAM.CUSTF) -
RECORDS(300 30) -
RECORDSIZE(53 53) KEYS(6 0) INDEXED)
/*
z/OS users:
click [Submit]. The form disappears and
the Jazz Workbench re-appears. When the
[Results] button turns green click this to review that that job has correctly
created the cluster.
Micro Focus users: when [JCL] is clicked this form disappears and the Jazz Workbench appears with the project button highlighted: -
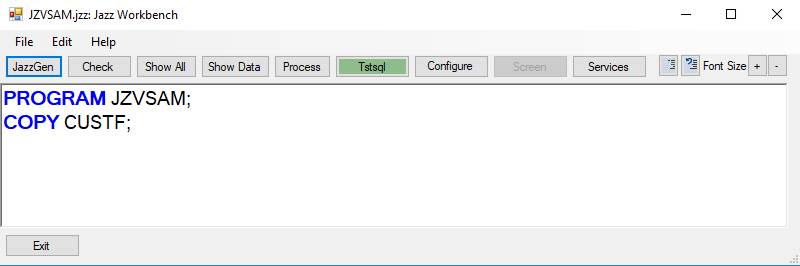
· Ignore program JZVSAM, but click the project (highlighted) button to open the MF Project. Import the item CUSTF.JCL using Add/Existing Item: -
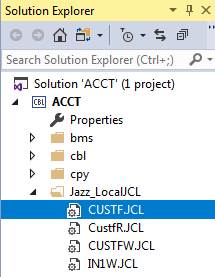
· Now submit this JCL. The VSAM cluster is created, but the alternate index and path still don’t exist.
· Click the output link to the job results and review the job output to check that the cluster has been created.
· Restart the MF Server. I’m not sure if this is necessary, but it has become my practice to restart the server after VSAM Create Cluster etc to avoid locking the cluster and so preventing following operations on the data set.
· Now compile and run the program to create data in the empty cluster. For files that have alternate indexes, note that this is done before you create the alternate indexes.
· If the file has any alternate indexes, the Jazz record definition will have DKEY or UKEY options defining them. CustF has a DKEY option on Name, allowing programs to retrieve records giving Name as a key value. To enable this function we must create the relevant AIX, which we do by returning to the [DataGen] Data/VSAM dialog with the same settings as before, except that now we check AIX. Click [JCL] and then run the job this creates, as previously described.
SQL
SQL tables must be defined to the database before you can compile and run your COBOL, and you need a Jazz record description to generate the COBOL. Method 1: you can use Jazz to create the SQL table definition, or Method 2, you can create the definition by some other means and use [JazzGen] Data/Import from SQL to create a Jazz definition which you may then edit.
If you have an existing table that you want to re-create, you can empty it with SQL DELETE tablename which will delete all data when there is no WHERE clause. However, unlike VSAM, the table does not have to be empty for you to WRITE to it, but you must be sure that you are not attempting to create records with the same primary key as another.
It is probably a good idea to create records in ascending primary key order.
Method 1. Jazz to SQL
Open a Jazz definition of an existing table, and edit this to change its name and prefix, and make any other edits that you want. Here we’ve edited PROJACT.jzc to PROJAC2.jcz, making the edits that are highlighted, and then saving it under its new name.
DEFINE PROJAC2 SQL DATA(
PROJNO CHAR(6) CAPS REQUIRED KEY,
ACTNO SMALLINT REQUIRED KEY PART 2,
ACSTAFF DECIMAL(5,2),
ACSTDATE DATE REQUIRED KEY PART 3,
ACENDATE DATE,
PERSON CHAR(30));
In the Jazz
workbench [Create SQL] appears to the right of [Configure] when you are editing
a SQL definition. Click this and Jazz
creates a SQL CREATE TABLE which opens in the default SQL editor (for me, SQL
Server management Studio): -
-- Last Updated by JazzUser at 8/07/2019 3:19:42 PM
--DEFINE PROJAC2 SQL PREFIX PJ2 DATA(
--PROJNO CHAR(6) CAPS REQUIRED KEY,
--ACTNO SMALLINT
REQUIRED KEY PART 2,
--ACSTAFF DECIMAL(5,2),
--ACSTDATE DATE
REQUIRED KEY PART 3,
--ACENDATE DATE,
--PERSON CHAR(30));
CREATE TABLE PROJAC2
(PROJNO CHAR(6) NOT NULL,
ACTNO
SMALLINT NOT NULL,
ACSTAFF DECIMAL(5,2),
ACSTDATE DATE NOT NULL,
ACENDATE DATE,
PERSON
CHAR(30),
PRIMARY KEY(PROJNO,ACTNO,ACSTDATE))
SQL Server management Studio is not appropriate to create a DB2 table, so I copied/pasted this into Notepad, edited out the stuff I did’t want (comments and line breaks between each line of the definition), and pasted it into the command window: -
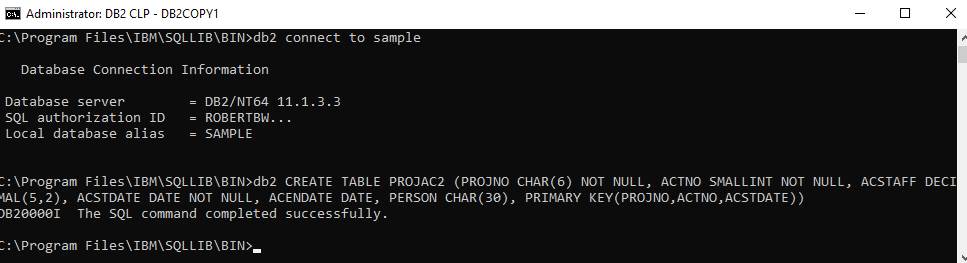
Method 2. SQL to Jazz
The table can be created directly in SQL with these commands
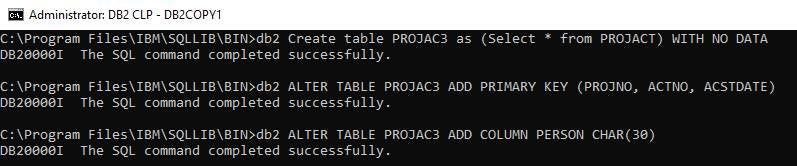
The Jazz description of the table can then be created with [Jazzgen] Data/Import from SQL. I found that when the table was created this way Jazz didn’t recognize the primary key, and I had to add the KEY properties as well as CAPS.
DEFINE PROJAC3 SQL
DATA(
PROJNO CHAR(6) CAPS KEY
REQUIRED,
ACTNO SMALLINT KEY PART
2 REQUIRED,
ACSTAFF MONEY(5,2),
ACSTDATE DATE KEY PART
3 REQUIRED,
ACENDATE DATE,
PERSON CHAR(30));