The
PROCESS Statement
Contents
Statement Options – Single-File PROCESS
Combining
WHERE, UNTIL, COUNT, and ORDER Options
Merge-Updating
Sequential Files
PROCESS retrieves, and may update, all the
records which satisfy a given condition. For example,
PROCESS Customer WHERE Customer.
PRINT (Customer.Name, Customer.Address, Customer.
END
PROCESS Customer;
PROCESS is an I/O loop that reads each record
that you want and processes it with the statements within the statement block.
At END PROCESS the record may be updated or copied, and then the next record is read. When all records
have been read (which may be straight away if there are none meeting the WHERE criteria, or the file is empty), statements (if
any) following END
PROCESS are executed.
For physical sequential files and VSAM the WHERE clause is a filter: every record is read and
brought back to the program, but those not meeting the WHERE
criteria are immediately discarded and the next record read. For SQL database tables the I/O logic may be able to use
indexes and selection logic to avoid returning unwanted records to the program
Statement Format
Single-File PROCESS: -
PROCESS File [WHERE (condition)] [UNTIL (condition)] [TS(nbr)]
[COUNT(field [BREAK]) | TALLY]
[ORDER(field list) | PREORDERED(field list) | [UPDATE] [COPY FileOut] SID(nn)
[SQL Options]
Multi-File PROCESS (SQL only)
PROCESS File[,file]… WHERE (condition) [UNTIL (condition)] [TS(nbr)] [COUNT(field [BREAK]) | TALLY]
[ORDER(field list) | PREORDERED(field list) | [COPY FileOut] SID(nn)
[SQL Options]
Each
“file” must have type SQL, the WHERE condition is required, and UPDATE is not available. Otherwise this is
the same as Single-file PROCESS, and will process a view of two
(or more) tables.
MERGE PROCESS
PROCESS File [SORT] [MERGE File2 [SORT] SKEYS
(File1Key1,File2Key1) [SEQCHECK]] [COPY FileOut] [COUNT(field)] SID(nn)
If MERGE is specified, then special rules apply. See PROCESS … MERGE below.
The File name, Customer in the example above, must be the
name of a previously defined record. This record must have type VSAM, ESDS, SQL, TS, or one of
the PSAM types: F, FB,
V, VB, or U. It cannot have type WorkingData, Screen,
System, etc.
For Physical Sequential types and VSAM
a PROCESS
statement must not appear within the scope of another PROCESS statement or a FOR
loop. It may however be within the scope of an IF statement. Thus the following
code is invalid unless Record2 is defined as TYPE(SQL): -
Process Record1;
Process
Record2 Where Record2.KeyValue =
Record1.KeyValue;
do something
End Process;
End Process;
PROCESS will process each record in the sequence that the system reads them. If this is not the correct sequence then you should use ORDER to ensure that records are correctly sequenced. For TYPE(SQL) this will insert an ORDER BY clause in the SQL SELECT statement. For VSAM and physical-sequential files ORDER will cause a sort to be used.
Statement
Options – Single-File PROCESS
WHERE
WHERE specifies a condition that must be true for a record to be considered. For example
DEFINE
D1 TYPE(FB) DATA(
F1 SMALLINT,
F2 CHAR(5),
F3 VARCHAR(15),
DT DATE);
PROCESS
D1 WHERE D1.F1 = 15;
Records for which the value of F1 is not 15 will be discarded. Only those with F1=15 will be passed on to the following statements within the PROCESS block.
Conditions follow the same rules as in IF statements. See Combining WHERE, UNTIL, COUNT, and ORDER Options if you’ve used more than one of these in your PROCESS statement.
UNTIL
UNTIL specifies a condition that, if true, will terminate the PROCESS loop, causing execution to resume after the END PROCESS statement. Conditions follow the same rules as in IF statements. See Combining WHERE, UNTIL, COUNT, and ORDER Options if you’ve used more than one of these in your PROCESS statement. You may also write an UNTIL condition on the END PROCESS statement: the condition is then tested at the end of the loop.
REOPEN
(Batch programs only). REOPEN causes the file to be closed and then opened for input. It is designed to handle situations like this, where initial logic produces a work file which is then processed later in the program. (MYFILE and WKFILE are both defined within COPY EZT-ESY-DATA): -
PROGRAM ESY3 BATCH EZT;
COPY EZT-ESY-DATA;
REPORT NAME 'SUMM-REPORT' HEADING
'EMPLOYEES SUMMARY SALARY REPORT ' WIDTH(80) ;
PROCESS MYFILE ORDER(MYFILE.GROUP2.BRANCH BREAK, MYFILE.GROUP2.JOB-CAT
BREAK);
MYFILE-WS.OLD-SAL =
MYFILE.SALARY;
IF MYFILE.JOB-CAT
= 10;
MYFILE-WS.RAISE-PCT =
7.00;
ELSE;
MYFILE-WS.RAISE-PCT =
9.00;
END IF;
WRKFILE.* = MyFile.* SIMPLE;
#207 I GROUP2.FIRST-NAME,GROUP2.BRANCH, included in
generic assignment
WRKFILE.* = MyFile-WS.* SIMPLE;
#207 I GROUP1.OLD-SAL,GROUP1.RAISE-PCT,GROUP1.RAISE-DOL,GROUP1.TOTAL-SAL,
included in generic assignment
WRITE Wrkfile;
#378 W Batch WRITE used - you may need to edit the JCL
PRINT (MYFILE.BRANCH,MYFILE.JOB-CAT,MYFILE-WS.OLD-SAL SUM,MYFILE-WS.TOTAL-SAL SUM,MYFILE-WS.RAISE-DOL SUM) LINE(01);
END PROCESS MYFILE;
PROCESS WKFILE ORDER(WKFILE.BRANCH BREAK, WKFILE.TOTAL-SAL DESC) REOPEN TALLY;
PRINT(WKFILE.BRANCH,WKFILE.FIRST-NAME,WKFILE.OLD-SAL SUM,WKFILE.RAISE-DOL
SUM,
WKFILE.RAISE-PCT AVG, WKFILE.TOTAL-SAL
SUM) REPORT(2);
END PROCESS WKFILE;
Without REOPEN the 2nd PROCESS loop would start reading WKFILE at its end, so would immediately terminate (end file).
TS(nbr)
(CICS programs only).
It is unlikely that you will write this option yourself, more likely
Jazz has inserted it.
In a classical CICS program a typical design uses a
scrolling area to display a set of records.
For example the screen may display some customer details, and a list of
current orders for that customer: -
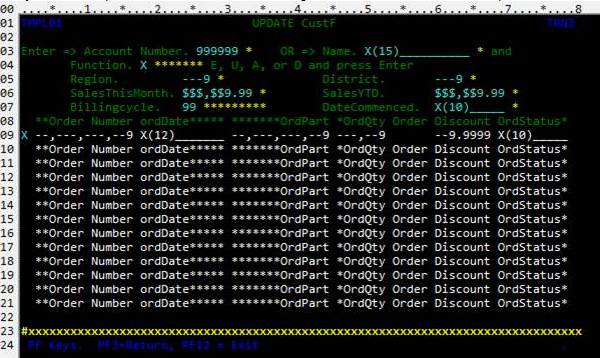
PROCESS
is used to read the set of records, but there may be
too many to display on the screen. For
example, here there are only enough lines to display 12 orders. What if there are more: for example, let’s
say a customer has 30 open orders? Your program needs a way of
keeping track of these records so that you can easily go forward or back
through them with PF8 (Down) and PF7 (Up).
Jazz does this by creating an in-memory TS file containing the record
keys, and it will add a definition of this file to your program, and this
option to the PROCESS
statement.
DEFINE
TS2 TYPE(TS) DATA(
OrdNbr
LIKE Orders.OrdNbr);
PROCESS
Orders WHERE(Orders.Ordnbr=CustF.Ordno) TS(2);
This is all automatic, and Jazz looks after creating this file, writing and reading records to it, using it to read particular records from Custf, and creating the visual clues like
![]()
at the bottom of your screen.
The statements between PROCESS and END PROCESS are executed as the records are processed from the TS file, i.e. for the up-to-12 records that can be displayed, not for the full 30 records. This needs to be considered if your logic counts or sums data: the calculated counts and sums will refer to the records displayed, not the full set.
COUNT(field)
COUNT names a field that counts the records that are processed by the PROCESS/END PROCESS loop. For example: -
DEFINE
WS DATA(
RNBR SMALLINT);
PROCESS
IN1 WHERE (IN1.Region > 5) ORDER(IN1.Region, IN1.District, IN1.Name) COUNT(WS.RNBR);
GET FR WHERE (FR.Region
= IN1.Region) ;
PRINT
(WS.RNBR, in1.region, FR.Name, in1.district, IN1.Name, in1.district, IN1.BillingCycle,
IN1.SalesThisMonth
SUM,IN1.SalesYTD SUM)
BREAK(in1.region, in1.district);
END PROCESS IN1;
The parentheses are optional: this could have been written COUNT WS.RNBR. It assigns the current record count to WS.RNBR. On completion on the process loop, it will contain the number of records that have been processed. This count is the count of records that were accepted by the WHERE, so that (in this example) the count will not include any records with IN1.Region <= 5. When ORDER is used then the COUNT field (WS.RNBR) reflects the sorted order, not the order in which the records were originally read from the file.
When the TS option is used to display a number of lines on a 3270-type screen then the record count will reflect the line number not the original record count. For example, consider this code fragment: -
DEFINE
TS2 TYPE(TS) DATA(
OrdNbr LIKE Orders.OrdNbr);
DEFINE
WS DATA(
Line
SMALLINT);
PROCESS
Orders WHERE (orders.ordcustid
= custf.account) TS(2) COUNT(WS.Line);
…
END PROCESS orders;
Imagine that for this customer there are 30 current orders but the screen only has room for 10 at a time. WS.Line will have a value from 1 to 10 within the PROCESS / END PROCESS. A WS.Line = 1 value might correspond to any of the 30 records read, depending on the user’s use of PF7/8 (up/down) and other processing.
The field named should have type SMALLINT in CICS, and SMALLINT or INTEGER for batch. You can use field names “JZ-Nxxx”, for example “JZ-N1” without defining them: these will be automatically defined for you as SMALLINT fields. You may refer to the COUNT field like any other number, but you should not change its value, and you should not use the same COUNT field in any other PROCESS or FOR statement.
COUNT (field BREAK)
COUNT field BREAK is only valid with REPORT programs, i.e. programs generated with the dialog Logic/Report Designer, as then the program has the correct structure and the counter can be incremented at the right time to be correct for each record within the break section. With COUNT sums.x BREAK calculations such as Average are easily written into routines like $R-END-District. See Sums, Counts, and Averages for more information.
Add BREAK when you want the count to be accumulated by control break level. When you write
PROCESS IN1 ORDER(IN1.Region BREAK,IN1.District BREAK,IN1.Name) REPORT COUNT ix BREAK;
this becomes
COUNT Sums.ix
BREAK
Values are accumulated into the Sums array, which will have extent 2 greater than the number of control break fields, i.e. in this case 4. When COBOL is generated, there will be a definition like this, including Sums.ix and fields which have been summed: -
003740 01
Sums.
Report1
003750 03 ix OCCURS 4 INDEXED BY JZIX2 PIC S9(4) COMP VALUE ZERO. Report1
003760 03 SalesThisMonth OCCURS 4 INDEXED BY JZIX3
PIC S9(9)V9(2) Report1
003770 COMP-3 VALUE ZERO. Report1
003780 03 SalesYTD OCCURS 4 INDEXED BY JZIX4 PIC S9(9)V9(2) COMP-3Report1
003790 VALUE ZERO. Report1
As records are read, values are accumulated into Sums.ix(1) etc. When there is a change of a control field, IN1.District or IN1.Region, the
values in xxx(1) are added into xxx(2) and then xxx(1) is set to zero. If it is IN1.Region that has changed, xxx(2) is also added into xxx(3) and
then set to zero.
See Combining WHERE, UNTIL, COUNT, and ORDER Options if you’ve used more than one of these in your PROCESS statement.
TALLY
TALLY is an alternative to COUNT. It differs
1. You don’t name a count field: it is called TALLY.
2. TALLY counts by control break, with the count being rolled up to the next level so that cumulative counts are available and averages can be calculated.
For example
PROCESS IN1 ORDER (IN1.Region BREAK, IN1.District BREAK, IN1.Name) TALLY;
PRINT(IN1.Region,IN1.District,IN1.Name,IN1.SalesYTD AVG, Sums.TALLY(1));
END PROCESS IN1;
This produces a report like this: -
1Printed at 28 Nov 2022, 09:25:37 RepNbr1 Page 9
0Region District *------------Salesperson's-------------*
*-----sales-----* *TALLY*
*Nbr-*
*-----------------Name-----------------* *------Year-----*
*----to date----*
…
10 6 District Subtotal $42,519.25 3
0 7
GLANVILLE, Ann
$73,891.44 0
GOULD,
John
$31,467.78 1
WILLIAMS,
Claude William
$21,520.48 2
WILLIAMSON, Norman Herbert James $423.76 3
10 7 District Subtotal $31,825.86 4
10 Region Subtotal $32,794.23 21
Grand
Total
$33,801.22 300
* * * END OF RepNbr1 * *
*
Note
1. TALLY is defined in a Sums record, as Sums.TALLY shows.
2. Subscript (1) refers to the count of the records in the current control break.
3. TALLY is incremented at the end of the PROCESS loop, so it counts from 0, not from 1.
4. TALLY is required if you use AVG (you will be prompted).
ORDER
| PREORDERED
(Batch programs only)
The ORDER option specifies the sequence in which the input is to be processed.
PROGRAM
Sort BATCH;
DEFINE
D1 TYPE(FB) DATA(
Region
SMALLINT,
District
SMALLINT,
Name CHAR(30),
PROCESS
D1 ORDER(D1.Region, D1.District, D1.Name);
PRINT
(D1.*);
END
PROCESS D1;
The ORDER option above will sort the records so that Regions will be in order from 1 to 9999. Within each Region, Districts will be in ascending order. Within each District, Names will be ascending order. Note that the order is defined by the collating sequence of the system: for CHAR fields on a mainframe using EBCDIC coding, lowercase letters come before uppercase letters which come before numbers, whereas most other systems use ASCII in which numbers come before uppercase letters which come before lowercase letters. To confuse things further, if the sort is done by SQL the ordering may ignore case.
With each field you can specify DESC if you want descending order instead of the default, ascending. Thus
PROCESS
D1 ORDER(D1.Region DESC, D1.District, D1.Name);
causes input to be processed from high D1.Region to low (or negative). Within this order, D1.District will continue to be processed in ascending order.
BREAK specifies that there will be a control break if the field changes, causing appropriate subtotals to be calculated and printed by PRINT statements within the loop. Thus
PROGRAM
aanexmpl BATCH;
COPY
IN1;
COPY
FR;
PROCESS
IN1 WHERE (IN1.Region = 1 | IN1.Region = 6)
ORDER (IN1.Region BREAK, IN1.District BREAK, IN1.Name) COUNT JZ.JZ-INDEX;
GET FR WHERE (FR.Region
= IN1.Region);
PRINT
(IN1.Region,FR.Name, IN1.District, IN1.Name, IN1.BillingCycle,
IN1.SalesThisMonth
SUM, IN1.SalesYTD SUM);
END
PROCESS IN1;
produces a report like this: -
Region *--------Region
Name---------* District *----Name-----* BillingCycle
*SalesThisMonth *--SalesYTD---*
1
1
1
1 District Subtotal 1
618.06 13,920.75
1
1
1 District Subtotal 2
412.04 9,280.50
Control breaks are only effective directly within PROCESS … END PROCESS. If the PRINT statement is tucked away in a ROUTINE, then the control breaks are ignored. With this logic: -
PROCESS
IN1 WHERE (IN1.Region = 1 | IN1.Region = 6)
ORDER (IN1.Region BREAK, IN1.District BREAK, IN1.Name) COUNT JZ.JZ-INDEX;
GET FR WHERE (FR.Region
= IN1.Region);
PERFORM
PrintLine;
END
PROCESS IN1;
ROUTINE
Printline;
PRINT
(IN1.Region,FR.Name, IN1.District, IN1.Name, IN1.BillingCycle,
IN1.SalesThisMonth
SUM, IN1.SalesYTD SUM);
END
ROUTINE Printline;
the report looks like this: -
Region *--------Region
Name---------* District *----Name-----* BillingCycle
*SalesThisMonth *--SalesYTD---*
1
1
1
1
1
1
…
6
6
Grand Total
8,858.86 199,530.75
See Combining WHERE, UNTIL, COUNT, and ORDER Options if you’ve used more than one of these in your PROCESS statement.
You need either ORDER or PREORDERED to specify control break fields, so if you want subtotals but the input is it’s already in the correct order, use PREORDERED in logic like this: -
PROCESS IN1 WHERE (IN1.Region = 1 | IN1.Region = 6)
PREORDERED (IN1.Region BREAK DESC, IN1.District BREAK, IN1.Name);
…
PRINT (IN1.Region,W.Region, IN1.District, IN1.Name, IN1.BillingCycle,
IN1.SalesThisMonth SUM, IN1.SalesYTD SUM);
END PROCESS IN1;
PREORDERED may not be used with SQL input, and has the same syntax as ORDER.
If PREORDERED is used and the input is not in the correct sequence, then the report program will be terminated. For example, this program
*# Last Updated by JAZZUSR at 28/01/2021
11:41:41 AM
PROGRAM aanexmpl BATCH;
…
PROCESS IN1 WHERE (IN1.Region = 1 | IN1.Region = 6)
PREORDERED (IN1.Region BREAK DESC, IN1.District BREAK, IN1.Name);
…
PRINT (IN1.Region,W.Region, IN1.District, IN1.Name, IN1.BillingCycle,
IN1.SalesThisMonth SUM, IN1.SalesYTD SUM);
END PROCESS IN1;
Produced this report: -
Printed at 28 Jan 2021, 11:37:09 RepNbr1 Page 1
Region *-Region-* District
*-----------------Name-----------------* BillingCycle
*SalesThisMonth-* *----SalesYTD---*
6 France 6 BARNES, Albert Paul Jun $994.87 $5,969.22
6 6 District Subtotal
$994.87 $5,969.22
6 Region Subtotal
$994.87 $5,969.22
1 New Zealan 5 BARNES, Caroline Jan $1,121.76 $1,121.76
PROGRAM TERMINATED.
SEQUENCE ERROR
ORDER(NULL)
ORDER(NULL) indicates that the input file is processed in its natural order, and you do not want another ORDER option to be added to this PROCESS statement. This is discussed in more detail in Easytrieve Conversion.
Combining
WHERE, UNTIL, COUNT, and ORDER Options
If you have used more than one of these options in your PROCESS statement then you may need to be aware of the order in which they are executed, and how they can interact.
The basic logic combining WHERE, UNTIL, and COUNT is a loop, in which logic
1. Reads the next (might be first) record and tests for End-of-file
2. Checks the UNTIL condition. If true, End-of-file is set true
3. The Process block (statements from PROCESS to END PROCESS) are executed if End-of-file is false and the WHERE condition is true
4. If COUNT is used, the first statement of the Process block will increment the COUNT variable.
Note that the order in which the options are processed has nothing to do with the order in which you write them. You’ll get the same results from
PROCESS file WHERE condition1 UNTIL condition2 COUNT IX1;
as you do from
PROCESS file COUNT IX1 UNTIL condition2 WHERE condition1;
or any other ordering of the statement options.
Because UNTIL (and WHERE) come before the Process block, but the index increment implied by a COUNT option is the first statement of the block, if the condition references the COUNT variable then the value tested may be one less than you expect. Thus
PROCESS IN1 UNTIL(Copy-Stats.Input.Count > 2) COUNT Copy-Stats.Input.Count;
causes THREE records to be processed, NOT two. It is for this reason that when a conversion program is generated with test mode checked the UNTIL clause is UNTIL(Copy-Stats.Input.Count > 0).
When the PROCESS contains ORDER then unless the file type is SQL it will use an explicit sort with input and output procedures. Jazz puts UNTIL and WHERE conditions into the input procedure so that unwanted records are discarded as soon as possible, while the Process block is put into the output procedure. This makes the generated program as efficient as possible, but can lead to some unexpected results. For example: -
PROCESS IN1
WHERE(IN1.Region <>
3) COUNT Copy-Stats.Input.Count ORDER(IN1.Region);
PRINT(In1.*);
END
PROCESS IN1;
With my test data this PROCESS statement will print 14 records for Region=1, 43 records for Region=2, none for Region=3, 26 for Region=4, and finally 3 records for Region=11. You might think that this simply adding UNTIL IN1.Region = 6 will produce the same results for regions 1, 2, 4 and 5 but then terminate. Instead I got these results: -
Printed at 06 Sep 2016, 00:18:46 Report1 Page 1
Region District *----Name-----* SalesThisMonth
*SalesYTD* BillingCycle DateCommenced
1 6 XXXXXXXXXXXXXXX 206.02 4,640.25
June 2013-06-11
2 3 YYYYYYYYYYYYYYY 206.02 4,640.25
April 2013-06-11
4 7 YYYYYYYYYYYYYYY 206.02 4,640.25
September 2013-06-11
4 10 YYYYYYYYYYYYYYY 206.02 4,640.25
June 2013-06-11
5 7 Delete 206.02 4,640.25
********* 2013-06-11
5 8 XXXXXXXXXXXXXXX 206.02 4,640.25
May 2013-06-11
7 9 YYYYYYYYYYYYYYY 206.02 4,640.25
November 2013-06-11
8 4 XXXXXXXXXXXXXXX 206.02 4,640.25
April 2013-06-11
9 7 XXXXXXXXXXXXXXX 206.02 4,640.25
March 2013-06-11
9 11 STURGESS,Shirle 206.02 4,640.25
June 2013-06-11
9 4 XXXXXXXXXXXXXXX 206.02 4,640.25
March 2013-06-11
10 6 MCNAUGHTON,Vera 206.02 4,640.25
February 2013-06-11
11 4 SIMPSON,Laura 206.02 4,640.25
April 2013-06-11
11 4 SIMPSON,Laura 206.02 4,640.25
April 2013-06-11
In the unsorted test data the first record for which IN1.Region = 6 was the 15th. Because UNTIL (and WHERE) are before the sort only the first 14 records were passed through it to the Process block containing PRINT(In1.*), giving the results shown.
Similarly,
PROCESS
IN1 WHERE(IN1.Region <> 3) COUNT Copy-Stats.Input.Count
ORDER(IN1.Region) UNTIL Copy-Stats.Input.Count >
2;
effectively ignores the UNTIL condition. This is because the statement
Copy-Stats.Input.Count += 1;
implied by the COUNT option is the first statement of the PROCESS block, and therefore is put in the output procedure. The value of Copy-Stats.Input.Count is always zero before the sort, so this condition is always false.
For file type SQL any sorting is handled implicitly by the database (DB2, Oracle), so WHERE and UNTIL are handled as they are for a basic unsorted file, whether or not the PROCESS contains ORDER.
SID(nn)
You will never write the SID option, it will be inserted automatically for you. However, you may need to understand what it does.
Every statement has a “Statement Index”, which is simply the number of the statement counting from the top. A recent enhancement (Build #292) documents this statement index as a comment, for example: -
PROGRAM Sample7 BATCH EZT;[13]
COPY EZT-Sample7-DATA;[14]
REPORT(1) NAME 'RPT1' HEADING('TITLE1','TITLE2 TITLE2' COL(3),'TITLE TITLE TITLE'
SPACE(1)) WIDTH(060) ;[18]
COPY JZSmth;[19]
PROCESS FILE1 ORDER(FILE1.GROUP2.TAL
BREAK) TALLY SID(19);[19]
IF FILE1.X1 = '7';[21]
CONTINUE PROCESS;[22]
END IF;[23]
PRINT (FILE1.TAL,Sums19.TALLY(1));[24]
END PROCESS FILE1;[25]
Thus the PROGRAM statement is the 13th statement – there
are several preceding statements that you’ll only see if you click [Show
all]. COPY EZT-Sample7-DATA;[14] is the next statement, REPORT is nbr 18, and so on. Knowing this number is useful in
understanding the generated COBOL because it is used to ensure unique names:
for example the COBOL corresponding to this program includes
003570 JZ-Main-Program-Logic. Sample7
003580*
PROCESS FILE1 ORDER(FILE1.GROUP2.TAL BREAK) TALLY Sample7
003590*
SID(19);[19]Sample7
003600 SORT SORTWORK
Sample7
003610 ON ASCENDING KEY TAL OF JZ-SORTWORK Sample7
003620 INPUT PROCEDURE IS JZ-19-PROCESSGroup-INPUT Sample7
003630 OUTPUT PROCEDURE IS JZ-19-PROCESSGroup-OUTPUT. Sample7
In the case of the PROCESS statement the number also affects the definition names for SUM and BREAK fields. You see this when you refer to these fields: I wrote
PRINT Tal, Tally;
This became
PRINT (FILE1.TAL,Sums19.TALLY(1));[24]
With earlier
builds this created a problem: when another statement was added before the PROCESS
statement, like the highlighted COPY JZSmth;[19] the statement index of the PROCESS
statement changed and the statement had to be edited to a new value, perhaps Sums20.TALLY.
To prevent this error, MANASYS inserts SID(19) to fix the statement index of the PROCESS statement as
19. It doesn’t matter that this
duplicates the statement index of the COPY statement. It would
however create errors if it was the same as another PROCESS statement. If this problem arises, remove the SID option and click
[Check] to have MANASYS add another one.
UPDATE
With UPDATE the record which has been read by the PROCESS may be updated at the END statement, before the next record is read. The file type must be VSAM, SQL, or XIO (which must be defined with an XREWRITE option). This option is invalid for PSAM file types (F, FB, V, VB, U). You write logic like this: -
PROCESS vsamfile UPDATE;
Vsamfile.field = newvalue;
END PROCESS vsamfile UPDATE;
Within the PROCESS loop you may not change the record’s key value, as this would create a new (and possibly duplicate) record.
The PROCESS statement only reads existing records, unlike GET it does not create new ones, so PROCESS file …. END PROCESS file UPDATE will not create any new records.
Note that it is the UPDATE on the END statement that is important, UPDATE can be omitted on the PROCESS statement itself.
For VSAM and XIO you may not use UPDATE and ORDER together. With ORDER Jazz will generate a sort and the original record is no longer available at the point in the program where the update would be done. This restriction does not apply to SQL.
Preventing Updates
As in a GET statement, you can prevent updates with UPDATE filename CANCEL: -
PROCESS
Vfile WHERE (Vfile.charfield = r2.charfield) UPDATE;
…
IF
Vfile.Region = 5;
UPDATE
Vfile CANCEL;
END IF;
END
PROCESS Vfile UPDATE;
PROCESS … MERGE
Process MERGE merges two sequential files based
on their sequence key. The files must be
in ascending sequence of this key. For
example
PROCESS FILE1 MERGE FILE2 SKEYS (FILE1.KEY1A,FILE2.KEY1B);
Prior to Build 291, instead of SKEYS an option ON was used
PROCESS FILE1 MERGE FILE2 ON FILE1.KEY1A=FILE2.KEY1B;
This option is obsolete and will become invalid
in future releases.
Statement Rules
·
The
SKEYS option list the sequence
fields. If there are several sequence
fields, then name all the fields for File1, followed by all the fields for
File2. For example
PROCESS In1 MERGE IN1Tran SKEYS (IN1.Region,IN1.District,IN1.Name,IN1Tran.Region,IN1Tran.District,IN1Tran.Name);
·
There
must be the same number of sequence keys for each file. In the example above, there are three.
·
Each
comparison must be valid. IF F1.A = F2.B would be invalid, then SKEYS (F1.A, F2.B) is invalid.
·
Sequence
keys must not have a dimension, and may not be groups.
·
The
first record from each file is read before the PROCESS loop starts, so the first execution of the loop handles these two
records. At the end of the loop, the
next record is read from EITHER FILE1 or FILE2, depending on
Read
FILE2 if FILE2.KEY1B <= FILE1.KEY1A
Else Read
FILE1
·
The
PROCESS loop finishes when both files have
reached End-of-file. See Merge Processing for an example.
·
If
necessary, use SORT to put either or both of the files
into the correct sequence. For example
PROCESS FILE1 SORT MERGE FILE2 SORT SKEYS(FILE1.KEY1A,FILE2.KEY1B);
Merge-Updating Sequential Files
You cannot
update records within a sequential file: instead you create a copy with
changes. For this, use PROCESS F1 MERGE F2 COPY F1Out; The first file is the Input Master File, the
second is the Transaction File. You cannot use a WHERE or ORDER options (but you can use SORT), and the Output file is defined
with LIKE.
This is
most easily explained through an example: -
PROGRAM Batch1 BATCH;
* You may need to edit these statements
COPY FILE1;
DEFINE FILEOUT LIKE FILE1;
#492 I DSNAME 'JAZZUSER.Files.FILEOUT'
COPY FILE2;
PROCESS FILE1 MERGE FILE2 SKEYS (FILE1.KEY1A,FILE2.KEY1B) COPY FILEOUT COUNT(IX);
IF FILEOUT.KEY1A
= FILE2.KEY1B;
FILEOUT.BALANCE +=
FILE2.PAYMENT;
END IF;
PRINT (JZ.IX, FILE1.*, FILE2.*, FILEOUT.*) ;
END PROCESS MERGE COPY FILEOUT;
Statement Rules
·
The
first file is considered to be the master file, and should have only one record
for each key value. If there are duplicate records (i.e. same key value)
in the master file, then all updates will be applied to the first record, and
others will be copied unchanged.
·
The
second file is the transaction file. It may contain any number of records for
any particular key value, and may include key values that are not represented
on the input master file.
·
The
logic critically depends on the master file and transaction file being
presented to the program in ascending key sequence. If the PROCESS
statement includes the option SEQCHECK, logic will be generated to check this, and
that there are no duplicates in File1.
If SORT, the file will be sorted into the appropriate
order. Either or both input files may
include either SEQCHECK or SORT.
·
The
output file, FILEOUT, MUST be defined with LIKE as it must
have exactly the same format as File1
·
Before
the PROCESS loop starts, the first record from both input
files is read. At the end the PROCESS
loop a record will be read from either FILE1 or FILE2. FILE1 is only read when it is greater, i.e.
if FILE1.KEY1A>FILE2.KEY1B
Comparing Keys
With a
single pair of keys you can use normal conditions to test whether File1 matches
File2, or has lower or higher key values, but there can be any number of key
pairs and this logic would become more complicated. Jazz provides a couple of special values
$CMerge compares
File1 and File2
$CMergeOut compares FileOut and
File2
These
values are 0 if the files match, +ve if File1/FileOut is greater than File2, and -ve
if less than. See https://www.jazzsoftware.co.nz/Docs/JazzLRMConditions.htm#SpecialValues
for more information.
Preventing Output
Default
logic for PROCESS … MERGE … COPY … will create a new record if a
transaction record has an unmatched key.
To prevent this, you need logic to detect this condition, and execute COPY-WANTED = false.
This example will update existing records, but not create new ones: -
PROCESS FILE1 MERGE FILE2 SKEYS (FILE1.KEY1A, FILE2.KEY1B) COPY FILEOUT COUNT JZ.IX1;
IF JZ.$CMergeOut = 0;
FILEOUT.BALANCE +=
FIle2.Payment;
IF JZ.$CMerge
> 0;
JZ.COPY-WANTED =
false;
END IF;
END IF;
PRINT (JZ.IX1, FILE1.*, FILE2.*, FILEOUT.*) ;
END PROCESS MERGE COPY FILEOUT;
SQL Options
Possible
enhancement: this is not currently
supported.
When
the input data has type SQL then the PROCESS statement will support extra
options, making available most of the power of SQL’s SELECT statement. The
following is envisaged: -
1.
The input may consist of one or several SQL tables. If there is more than one table, then 2nd
(etc) tables are related through a JOIN condition. For example
PROCESS Table1 JOIN-type Table2 ON
(Join-relationship)
a. Join-Relationship is one
or more equality conditions relating the two table, for example
i. PROCESS Custf JOIN Orders ON (Custf.Account
= Orders.OrdCustid)
Comparison operators other than “=”
are invalid
If there are multiple conditions,
they must be related by the boolean operator &
(AND)
b. JOIN-type is JOIN |
LEFTJOIN.
i. JOIN => if there are
no records satisfying the JOIN relationship, then nothing is returned, and the
PROCESS/ENDPROCESS is terminated
ii. LEFTJOIN => If there
are no records satisfying the JOIN relationship, then the PROCESS is executed
once for the Table1 record, with an initialised Table2 record
iii. There are no current
plans to implement RIGHTJOIN
2.
GROUP (field [,field]…) causes the data to be grouped by the field(s)
named. If ORDER is also present then
the GROUP fields must be all or a left subset of the fields named in
ORDER. If ORDER is absent then GROUP
implies ORDER with the same field list.
3.
HAVING (condition). Like WHERE,
except that this applies to the group so that it can check for conditions like
$COUNT > 0 and $SUM(field) > 0.
HAVING is only valid if GROUP is also present.
4.
In HAVING conditions the SQL aggregate functions supported by the
database are available: they are referenced as $COUNT, $SUM, $MAX, $MIN and
$AVG.